From Question toVerified Answer
For Decision Makers
Most AI tools match your question to similar text. That works for simple lookups — but falls apart on complex questions, multi-document reasoning, or anything requiring verification.
Courdx runs three retrieval strategies in parallel, validates every result, and cites every fact to the exact source sentence. You get answers you can trust — not answers you have to double-check.
For Technical Teams
The entire pipeline is orchestrated as a series of coordinated AI workflows — not a single monolithic prompt chain. Each stage is independently configurable, observable, and tuneable from the admin panel.
Meaning-based search with multiple AI models, knowledge graph traversal for entity relationships, exact keyword matching, AI relevance scoring, self-correcting retrieval, and built-in quality evaluation — all running in a production-grade pipeline.
The RAG Pipeline
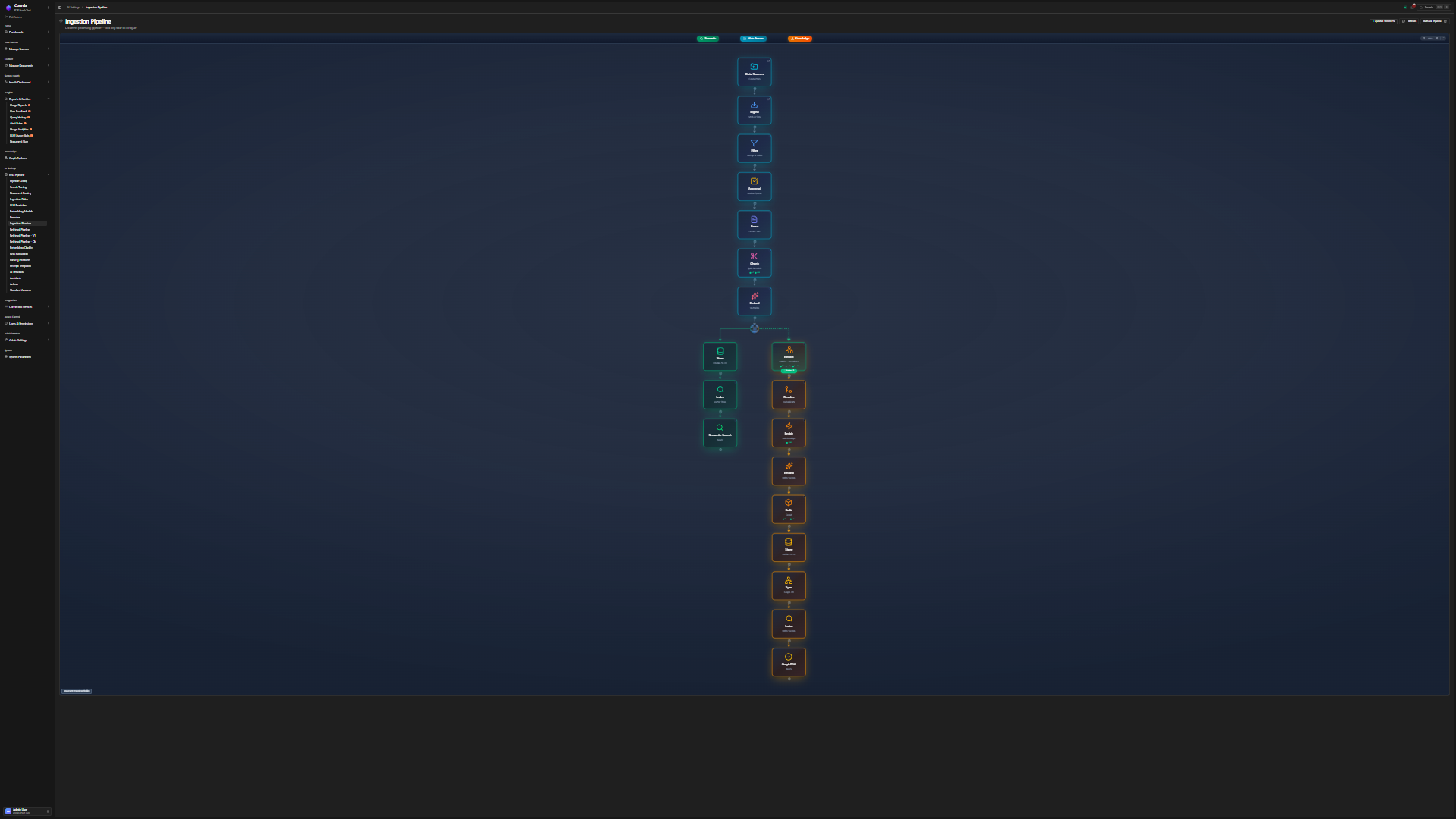
Every Query. Five Stages, Nine Steps.
Nine steps grouped into five intelligent stages. Hover over each node to explore the pipeline — notice how three retrieval strategies branch in parallel, then converge through fusion and validation.
Data Flow
From Raw Document to Searchable Knowledge
Every document goes through ingestion, parsing, chunking, entity extraction, embedding, and indexing — fully automated.
Three Pillars of Intelligent Retrieval
Each pillar solves a fundamental problem that basic retrieval systems ignore.
Intelligent Retrieval
We Don't Just Search. We Understand.
Five layers of intelligence between your question and your answer: complex questions are broken apart into focused sub-questions, predictive search generates ideal answer shapes before retrieving, multiple search approaches run in parallel across meaning, keywords, and document connections, an AI relevance model scores which results truly answer the question, and self-correcting AI catches low-confidence results and refines them automatically.
Knowledge Graph
See the Connections Others Miss
Courdx automatically extracts entities and relationships from your documents and builds a knowledge graph. Community detection clusters related entities into groups — so you can ask big-picture questions like "what themes recur across our compliance reports?" that basic search can't touch.
Trust & Citations
Every Fact. Every Source. Verified.
Every claim cites the exact sentence in the source document — not just "found in Document 3." Confidence scores tell you how strong each citation is. Input and output guardrails block prompt injection, PII leaks, and hallucinated content. Full audit trail for compliance.
Multi-Dimensional Retrieval
Not Just Vector Search. Multi-Strategy Intelligence.
A single retrieval method always has blind spots. Vector search misses exact terms. Keyword search misses synonyms. Neither understands entity relationships.
Courdx runs all three simultaneously and fuses the results with intelligent ranking — so you get the best of every approach in one ranked list.
Semantic Understanding
Meaning-based search captures intent beyond keywords
Graph Reasoning
Knowledge graph reveals entity relationships across documents
Keyword Precision
Exact matching for codes, identifiers, and specific phrases
Query Intelligence
Predictive search + decomposition + smart routing
Step by Step
The Complete Journey
From natural language question to verified, cited answer — the five stages that power every query.
Your Question
Natural language query — plain English, no syntax required
Query Decomposition
Complex questions are broken into focused sub-queries. Each part gets its own retrieval pass.
- Predictive search generates ideal answer shapes before retrieving documents
- Expands acronyms, synonyms, and domain-specific terms
- Routes each sub-query to the optimal retrieval strategy
Multi-Strategy Retrieval
Three search strategies run in parallel — each catching what the others miss.
- Meaning-based search across multiple AI models for deep semantic understanding
- Knowledge graph traversal surfaces entity relationships across documents
- Exact keyword matching for codes, names, identifiers, and specific phrases
- Intelligent result fusion merges all outputs into one optimized ranking
Intelligent Validation
Every result is scored, reranked, and validated before the AI writes its answer.
- An AI relevance model scores each result for true match quality — not just surface similarity
- Low confidence triggers self-correcting retrieval with automatic query refinement and retry
- Falls back to web search if internal sources are insufficient
- Built-in accuracy checks measure faithfulness, relevance, and answer quality
Cited, Verified Response
The final answer is synthesized from validated sources with mandatory citations.
- Every fact cited to the exact sentence in the source document
- Confidence score per citation — not just per answer
- Output guardrails check for hallucinations, PII leaks, and toxic content
- Full audit trail: who asked, what was retrieved, what was generated
Measurable Results
Up to 95% Accuracy. Measured.
Each search strategy catches what the others miss. Combined with AI relevance scoring and self-correcting retrieval, the multi-strategy approach closes the gaps that make basic AI search unreliable.
Verifiable Answers
Every Fact. Every Source. Verified.
Click any citation to see the exact source sentence highlighted in context. No more "the AI said so."
The company achieved $2.4M in Q3 revenue[1], representing a 23% YoY growth[2]. The main drivers were the new enterprise contracts signed in July and August[3].
Hover over highlighted text to see source
“$2.4M in Q3 revenue”
“23% YoY growth”
“enterprise contracts signed in July and August”
Every fact in Courdx responses is traced back to the exact sentence in your source documents
Visual Pipeline
9 Steps. 5 Stages. Fully Configurable.
Documents flow through parsing, chunking, embedding, and knowledge graph extraction — each step configurable from the admin panel.
Observable Pipeline
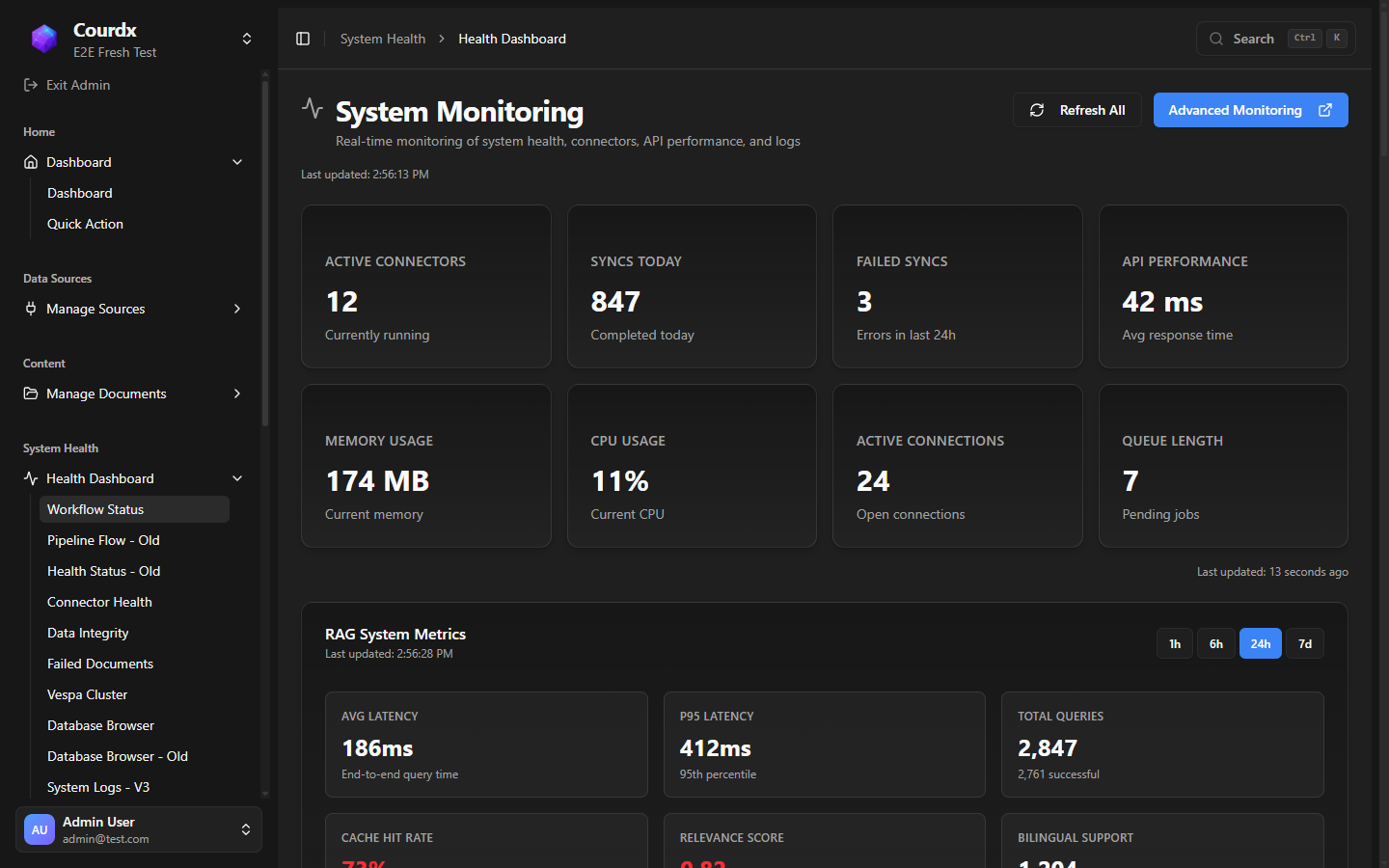
Watch It Work. In Real Time.
Courdx isn't a black box. The admin panel includes 15 dedicated health pages showing real-time system metrics, retrieval quality, and cost analytics. You see exactly what the system is doing — and where to tune it.
Research-Backed
Built on Peer-Reviewed Research
Not prompt engineering. Real retrieval science, implemented in production.
Knowledge Graph Reasoning
Clusters related entities for big-picture questions across documents
Self-Correcting Retrieval
Refines the question and tries again when confidence drops
AI Relevance Scoring
Deep relevance evaluation, not just surface similarity
Intelligent Result Fusion
Merges multiple search strategies into one optimal ranking
Predictive Search
Generates the ideal answer shape first, then finds matching documents
Query Decomposition
Breaks complex questions into precisely answerable parts
AI Workflow Orchestration
Multiple workflows coordinate retrieval and validation
Built-in Quality Evaluation
Automated accuracy measurement: faithfulness, relevance, answer quality
See the Pipeline In Action
Bring your hardest question and your real documents. We'll trace the entire retrieval pipeline live.