Enterprise-Ready From Day One
36+ admin pages, 14 retrieval configuration screens, 15 health monitoring dashboards, 7 analytics views. Everything you need to deploy, tune, and operate knowledge retrieval at enterprise scale.
Intelligent AI Pipelines
Self-correcting retrieval that decomposes, validates, and refines every answer automatically
Multi-Strategy Retrieval
Vector, keyword, and knowledge graph search fused into one ranking
Enterprise Security
On-prem deployment, DLP policies, and collection-level access control
36+ Admin Pages
Full control panel: health monitoring, analytics, retrieval tuning, and more
Capabilities
Complete Feature Set
Not a wrapper around a single AI model. A production platform with deep configurability for teams that need to tune, monitor, and trust their AI.
Intelligent Chat Interface
- Real-time streaming responses
- Confidence indicators on every answer
- Citation tooltips with source preview
- Conversation history with search
- Project/folder organization
- File attachments and drag-drop
AI Assistants (Personas)
- Custom system prompts per use case
- Task-specific instruction templates
- A/B testing different prompts (Prompt Lab)
- Per-channel configuration for Slack
- Version control for prompt changes
Document Intelligence
- Semantic chunking — splitting documents by meaning, not arbitrary length
- Automatic duplicate detection
- Quality scoring before indexing
- PII detection and redaction
- Metadata extraction
Analytics & Insights (7 Pages)
- AI usage stats: costs, model distribution, trends
- Query history with relevance scoring
- User feedback and satisfaction tracking
- Alert rules for anomaly detection
- Document statistics and coverage analysis
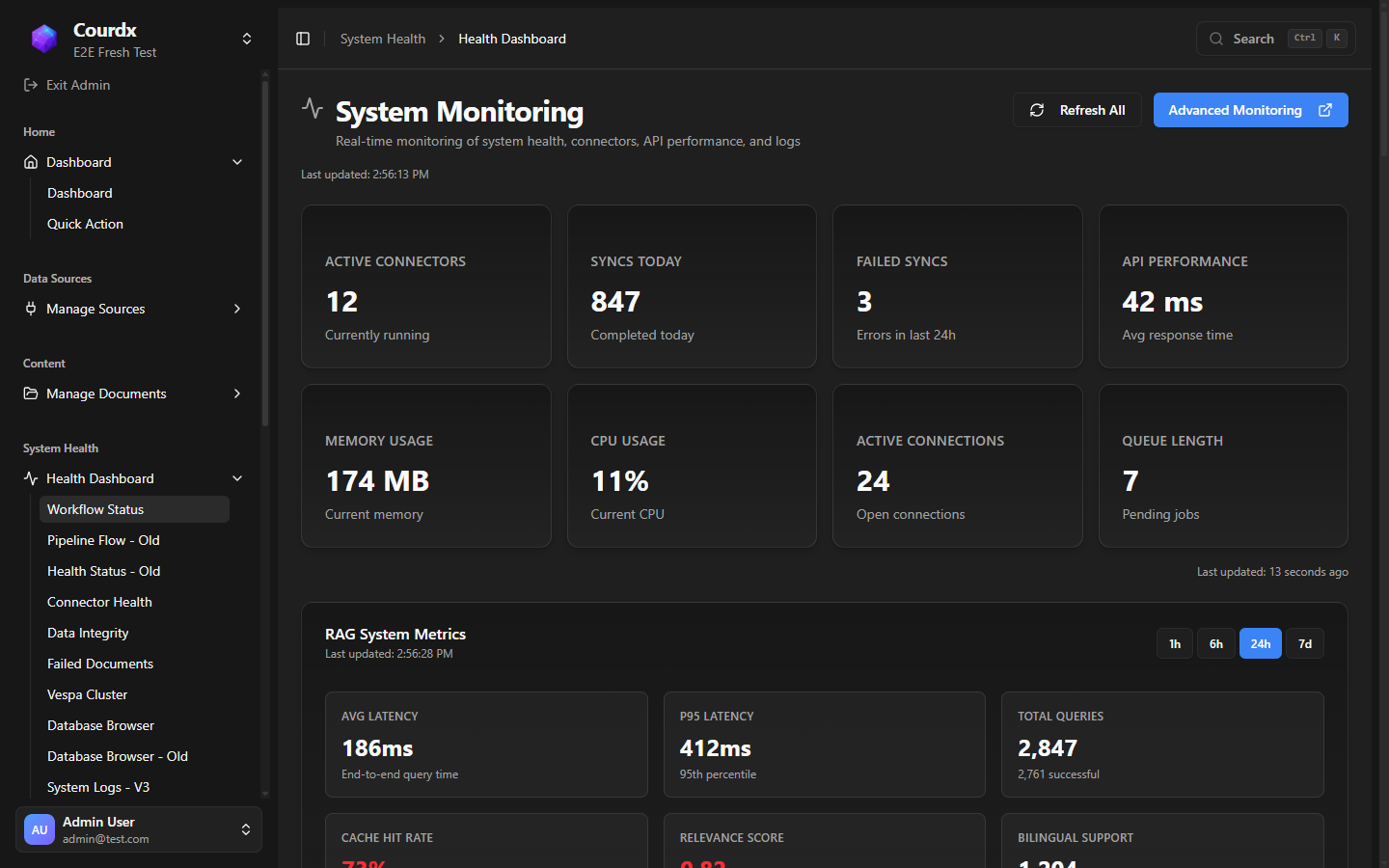
System Health (15 Pages)
- Real-time CPU, memory, and queue monitoring
- Search engine health and document indexing status
- Failed document tracking and retry
- Connector health across every integrated source
- Database browser and system logs
- Document parsing metrics and error analysis
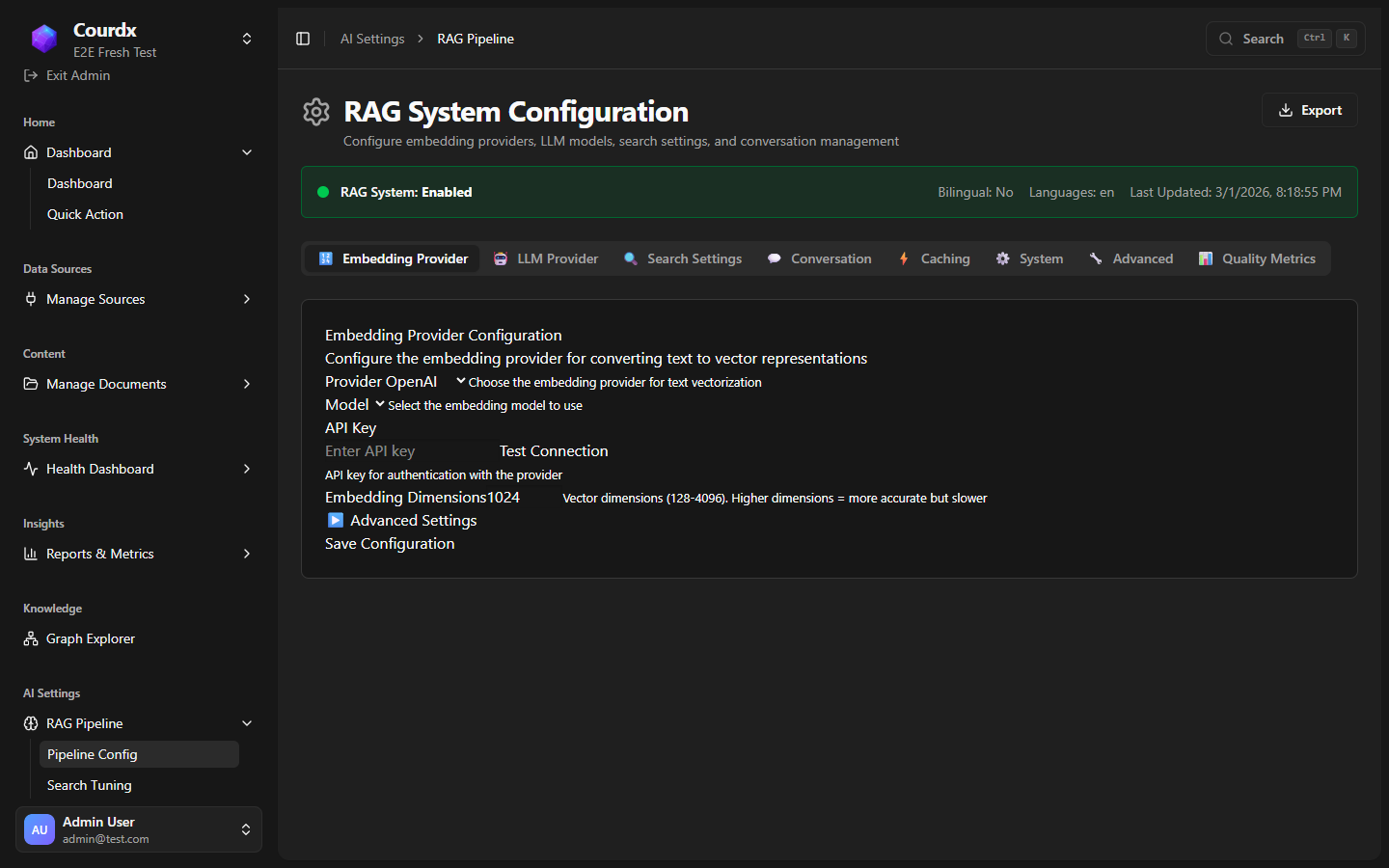
Retrieval Configuration (14 Pages)
- Six AI models to choose from for meaning-based search
- Choose between cloud AI and local AI models for any task
- Four document parsing engines for every file format
- Hybrid search tuning with knowledge graph weighting
- Built-in accuracy checks measure response quality automatically
- Guardrail sensitivity tuning (input + output)
Real Product
See the Actual Interface
No mockups. These are real screenshots from a running Courdx deployment.
What Makes These Features Different?
Learn about the intelligent retrieval, knowledge graph, and trust systems that power Courdx.
See These Features In Action
Schedule a demo to explore the full platform with your team.